Each resource type in Azure has a naming scope within which the resource name must be unique. For PaaS resources such as Azure SQL Server (server for Azure SQL DB) and Azure Data Factory, the name must be globally unique within the resource type. This means that you can’t have two data factories with the same name, but you can have a data factory and a SQL server with the same name. Virtual machine names must be unique within the resource group. Azure Storage accounts must be globally unique. Azure SQL Databases should be unique within the server.
Since Azure allows you to create a data factory and a SQL server with the same resource name, you may think this is fine. But you may want to avoid this, especially if you plan on using system-defined managed identities or using Azure PowerShell/CLI. And if you aren’t planning on using these things, you might want to reconsider.
I ran into this issue of resources with the same name in a client environment and then recreated it in my Azure subscription to better understand it.
I already had a data factory named adf-deploydemo-dev so I made an Azure SQL server named adf-deploydemo-dev and added a database with the same name.

Azure Data Factory should automatically create its system-assigned managed identity. It will use the resource name for the name of the service principal. When you go to create a linked service in Azure Data Factory Studio and choose to use Managed Identity as the authentication method, you will see the name and object ID of the managed identity.

For the Azure SQL Server, we can create a managed identity using PowerShell. The Set-AzSqlServer cmdlet has an -AssignIdentity parameter, which creates the system-assigned managed identity.

If you use Get-AzSqlServer to retrieve the information and assign the Identity property to a variable, you can then see the system-assigned managed identity and its application ID.

Now when I look in Active Directory, I can see both managed identities have the same name but different application IDs and object IDs.

Everything is technically working right now, but I have introduced some needless ambiguity that can cause misunderstandings and issues.
Let’s say that I want to grant the Storage Blob Data Reader role to my data factory. I go to the storage account, choose to add a role assignment, select the role, and then go to add members. This is what I see:
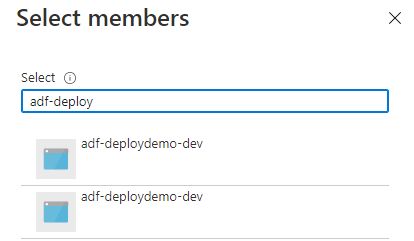
Or let’s say that I use PowerShell to get lists of resources by name. I may be locating resources to add tags, add a resource lock, or move the resource to another region or resource group.

If I don’t specify the resource type, I will get my data factory, my database, and my server in the results. You may be saying “Well, I would always specify the type.” Even if that is true, are you sure all coworkers and consultants touching your Azure resources would do the same?
Why introduce this ambiguity when there is no need to do so?
There are some good tips in the Cloud Adoption Framework in Microsoft Docs about naming conventions. Your organization probably wants to decide up front what names are acceptable and then use Azure Policy as well as good processes to ensure adherence to your defined conventions. And if I were the consultant advising you, I would suggest that resources within your tenant be unique across resource types. The suggestion in Docs is to use a resource type abbreviation at the beginning of your resource name. That would avoid the issue I have demonstrated above. Naming conventions should be adjusted to your organization’s needs, but the ones suggested in Docs are a good place to start if you need some help. It is beneficial to have some kind of resource naming convention beyond just whatever is allowed by Azure.
One Comment