I’ve been working on building my Biml library over the last few months. One of the first design patterns I created was a Type 1 Slowly Changing Dimension where all fields except the key fields that define the level of granularity are overwritten with updated values. It assumes I have a staging table, but it could probably be easily modified to pull directly from the source table if needed.
For simplicity, I’m going to create DimSalesReason from the AdventureWorks database as my example. Please pardon the large amount of code in this post. I wanted to provide a fairly complete picture so you can see how the pieces fit together so I’m providing all of the SQL and Biml needed to generate the package.
Required Database Objects
My staging table is a copy of source table and looks like this:
CREATE TABLE [Staging].[SalesReason](
[SalesReasonID] [int] NOT NULL,
[Name] [nvarchar](50) NOT NULL,
[ReasonType] [nvarchar](50) NOT NULL,
[ModifiedDate] [datetime] NOT NULL
)
Here is the DDL for my dimension table:
CREATE TABLE [dbo].[DimSalesReason](
[SalesReasonKey] int IDENTITY(1,1) NOT NULL Primary Key
,[SalesReasonID] int not null
,[SalesReasonName] nvarchar(50) not null
,[SalesReasonType] nvarchar(50) not null
,[HistoricalHashKey] varbinary(20) NOT NULL
,[ChangeHashKey] varbinary(20) NOT NULL
,[InsertDttm] datetime not null
,[UpdateDttm] datetime NULL
)
You’ll notice I have some audit fields in my table. UpdateDttm is the datetime when the row was last updated. InsertDttm is the datetime when the row was initially inserted. The HistoricalHashKey and ChangeHashKey are used for change detection. I may not need them in a dimension this simple, but I use them in larger/wider dimensions and I like my dimensions to be built consistently (unless they need to be tweaked for performance). The HistoricalHashKey represents the business key of the table that defines the level of uniqueness for the row in the dimension table. The ChangeHashKey represents all the other fields that are used in the dimension row. This makes it easier to determine if values have changed since I can compare just the ChangeHashKey instead of each individual field.
I also have an update table. This allows me to update in bulk rather than updating in place row by row. With a very small table, you might not notice a performance difference, but this pattern becomes much more efficient as the table grows.
CREATE TABLE [Updt].[UpdtSalesReason]( [SalesReasonID] int not null ,[SalesReasonName] nvarchar(50) not null ,[SalesReasonType] nvarchar(50) not null ,[HistoricalHashKey] varbinary(20) NOT NULL ,[ChangeHashKey] varbinary(20) NOT NULL ,[InsertDttm] datetime not null )
I use a view to do most of the transformation work (joins, business logic, etc.) for my Type 1 SCD package. Here’s my view for the SalesReasonDimension:
Create View [Staging].[DimSalesReason] as
With SalesReasonData as (
Select [SalesReasonID]
,[Name] as [SalesReasonName]
,[ReasonType] as [SalesReasonType]
,CONVERT(VARBINARY(20), HASHBYTES('MD5', CONCAT(SalesReasonID, ' ')))
AS [HistoricalHashKey]
,CONVERT(VARBINARY(20), HASHBYTES('MD5', CONCAT(Name, ' ', ReasonType)))
AS [ChangeHashKey]
,CURRENT_TIMESTAMP as InsertDttm
,CURRENT_TIMESTAMP as UpdtDttm
from
[Staging].[SalesReason]
UNION
Select -1 as [SalesReasonID]
, 'Unknown' as [SalesReasonName]
, 'Unknown' as [SalesReasonType]
,CONVERT(VARBINARY(20), HASHBYTES('MD5', CONCAT(-1, ' ')))
AS [HistoricalHashKey]
,CONVERT(VARBINARY(20), HASHBYTES('MD5', CONCAT('Unknown', ' ', 'Unknown')))
AS [ChangeHashKey]
,CURRENT_TIMESTAMP as InsertDttm
,CURRENT_TIMESTAMP as UpdtDttm
)
Select SalesReasonID
, SalesReasonName
, SalesReasonType
, HistoricalHashKey
, ChangeHashKey
, CONVERT(VARCHAR(34), HistoricalHashKey, 1) AS HistoricalHashKeyASCII
, CONVERT(VARCHAR(34), ChangeHashKey, 1) AS ChangeHashKeyASCII
, InsertDttm
, UpdtDttm
from SalesReasonData
Using a view to do the transformation work allows me to use the SQL Server engine to do the things it is good at (joins, case statements, conversions) and SSIS to do the things it is good at (controlling the flow of data). It also makes it easy to create a design pattern in Biml that is abstract enough that it easily fits most SCD 1 scenarios. The hashkey fields allow me to do a lookup on one field to determine if the row already exists in the dimension table and a quick comparison to determine if any of the values for that row have changed. I chose to use an MD5 hash because I think it is a good balance of speed/size and collision risk. You may feel differently (others prefer SHA1 due to lower collision risk). On a dimension this size, the difference probably isn’t noticeable.
You can also see that I add my unknown member row in my view. Some people prefer to set the surrogate key of the unknown value to -1. I prefer to set the business key to -1 and let the surrogate key be set to any value in the load process. I’m not a fan of having to turn off the identity insert to add the unknown row. When I do the dimension key lookup for fact tables, I just look for the row where the business key = -1. This also means I don’t have to check my dimension tables to see if someone remembered to insert the unknown rows after deployment to a new environment because I know the unknown rows will be inserted when the package is run.
I have audit steps in my package that write to the Audit.PackageControl table using stored procedures.
CREATE TABLE [Audit].[Package_Control](
[Package_NM] [varchar](100) NOT NULL,
[Package_ID] [uniqueidentifier] NOT NULL,
[Parent_Package_ID] [uniqueidentifier] NULL,
[Execution_ID] [bigint] NULL,
[Start_TS] [datetime] NOT NULL,
[Stop_TS] [datetime] NULL,
[Insert_Row_QT] [int] NULL,
[Update_Row_QT] [int] NULL,
[Unchanged_Row_QT] [int] NULL,
[Deleted_Row_QT] [int] NULL,
[Duration_s] AS (datediff(second,[Start_TS],[Stop_TS])),
[PackageLogID] [int] IDENTITY(1,1) NOT NULL
)
CREATE PROCEDURE [Audit].[PackageControlStart]
(
@PackageName varchar(100)
, @PackageId uniqueidentifier
, @ParentPackageId uniqueidentifier = NULL
, @ExecutionId bigint
, @StartTime DATETIME
, @StopTime datetime = NULL
, @InsertRowQuantity int = NULL
, @UpdateRowQuantity int = NULL
, @UnchangedRowQuantity int = NULL
)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @PackageLogId int
INSERT INTO [Audit].[Package_Control]
(
[Package_NM]
, [Package_ID]
, [Parent_Package_ID]
, [Execution_ID]
, [Start_TS]
, [Stop_TS]
, [Insert_Row_QT]
, [Update_Row_QT]
, [Unchanged_Row_QT]
)
SELECT
@PackageName
, @PackageId
, @ParentPackageId
, @ExecutionId
, CURRENT_TIMESTAMP
, @StopTime
, @InsertRowQuantity
, @UpdateRowQuantity
, @UnchangedRowQuantity
SELECT @PackageLogID = SCOPE_IDENTITY()
SELECT @PackageLogID as PackageLogID
END
CREATE PROCEDURE [Audit].[PackageControlStop]
(
@PackageId uniqueidentifier
, @ExecutionId bigint
, @InsertRowQuantity int = NULL
, @UpdateRowQuantity int = NULL
, @UnchangedRowQuantity int = NULL
)
AS
BEGIN
SET NOCOUNT ON;
-- Close out the execution.
UPDATE PC
SET [Stop_TS] = CURRENT_TIMESTAMP
, [Insert_Row_QT] = @InsertRowQuantity
, [Update_Row_QT] = @UpdateRowQuantity
, [Unchanged_Row_QT] = @UnchangedRowQuantity
FROM [Audit].[Package_Control] AS PC
WHERE PC.Package_ID = @PackageId
AND PC.Execution_ID = @ExecutionId
AND PC.[Stop_TS] IS NULL;
END
And Now for the Biml
My Biml library usually contains 3 files for each package type:
- ProjectConnections – I like to keep my connection managers in a separate file so I only have to update one place if I need to add or change a connection.
- Dim1 – This contains my actual design pattern.
- CreateDim1 – This is the Biml file I run to generate the package. It gets separated so I can pull values from databases and pass in variables to my design pattern using BimlScript. For this example I have hardcoded my variables into this file rather than pulling from a database.
ProjectConnections.Biml
<#@ template language="C#" tier="1" #>
<Connections>
<OleDbConnection Name="AWBIML" ConnectionString ="Data Source=localhost\SQL2014;
Initial Catalog=AWBIML;Integrated Security=SSPI;Provider=SQLNCLI11.1;" CreateInProject="true"/>
<OleDbConnection Name="Audit" ConnectionString ="Data Source=localhost\SQL2014;
Initial Catalog=AWBIML;Integrated Security=SSPI;Provider=SQLNCLI11.1;" CreateInProject="true"/>
</Connections>
The ProjectConnections file doesn’t begin with Biml tags because it gets included in the middle of the CreateDim1.biml file. AWBIML is a local database I created to contain my data mart.
Dim1.Biml
<#@ template language="C#" tier="2" #>
<#@ property name="PackageName" type="String" #>
<#@ property name="DstSchemaName" type="String" #>
<#@ property name="DstTableName" type="String" #>
<#@ property name="DstConnection" type="String" #>
<#@ property name="DataFlowSourceName" type="String" #>
<#@ property name="SrcConnection" type="String" #>
<#@ property name="SourceQuery" type="String" #>
<#@ property name="UpdateSchemaName" type="String" #>
<#@ property name="UpdateTableName" type="String" #>
<#@ property name="UpdateConnection" type="String" #>
<#@ property name="UpdateSQLStatement" type="String" #>
<Package Name="<#=PackageName#>" Language="None">
<Parameters>
<Parameter DataType="String" Name="ParentPackageID">00000000-0000-0000-0000-000000000000</Parameter>
</Parameters>
<Variables>
<Variable EvaluateAsExpression="true" DataType="String"
Name="QualifiedTableSchema">"["+@[User::SchemaName]+"].["+@[User::TableName]+"]"
</Variable>
<Variable DataType="String" Name="QueryAuditStart">
EXECUTE [Audit].[PackageControlStart] @PackageName=?, @PackageId=?,
@ParentPackageId=?,@ExecutionId=?, @StartTime=?;
</Variable>
<Variable DataType="String" Name="QueryAuditUpdate">
EXECUTE [Audit].[PackageControlStop] @PackageId=?, @ExecutionId=?,
@InsertRowQuantity=?, @UpdateRowQuantity=?, @UnchangedRowQuantity=?;</Variable>
<Variable DataType="Int32" Name="RowCountChanged">0</Variable>
<Variable DataType="Int32" Name="RowCountNew">0</Variable>
<Variable DataType="Int32" Name="RowCountSource">0</Variable>
<Variable DataType="Int32" Name="RowCountUnchanged">0</Variable>
<Variable DataType="String" Name="SchemaName"><#=DstSchemaName#></Variable>
<Variable DataType="String" Name="TableName"><#=DstTableName#></Variable>
</Variables>
<Tasks>
<ExecuteSQL Name="SQL Begin Audit" ConnectionName="Audit">
<VariableInput VariableName="User.QueryAuditStart" />
<Parameters>
<Parameter Name="0" VariableName="System.PackageName" DataType="String" Length="-1"/>
<Parameter Name="1" VariableName="System.PackageID" DataType="Guid" Length="-1"/>
<Parameter Name="2" VariableName="ParentPackageID" DataType="Guid" Length="-1"/>
<Parameter Name="3" VariableName="System.ServerExecutionID" DataType="Int64"
Length="-1"/>
<Parameter Name="4" VariableName="System.StartTime" DataType="Date" Length="-1"/>
</Parameters>
</ExecuteSQL>
<ExecuteSQL Name="SQL Truncate <#=UpdateTableName#>"
ConnectionName="<#=UpdateConnection#>">
<DirectInput>Truncate Table [<#=UpdateSchemaName#>].[<#=UpdateTableName#>]
</DirectInput>
<PrecedenceConstraints>
<Inputs>
<Input OutputPathName="SQL Begin Audit.Output" />
</Inputs>
</PrecedenceConstraints>
</ExecuteSQL>
<Dataflow Name="DFT Insert<#=DstTableName#>">
<Transformations>
<RowCount Name="CNT Changed_Rows" VariableName="User.RowCountChanged">
<InputPath OutputPathName="CSPL Check For Changes.ChangedRows" />
</RowCount>
<ConditionalSplit Name="CSPL Check For Changes">
<InputPath OutputPathName="LKP Historical Key.Match" />
<OutputPaths>
<OutputPath Name="ChangedRows">
<Expression>ChangeHashKeyASCII != lkp_ChangeHashKeyASCII</Expression>
</OutputPath>
</OutputPaths>
</ConditionalSplit>
<RowCount Name="CNT New_Rows" VariableName="User.RowCountNew">
<InputPath OutputPathName="LKP Historical Key.NoMatch" />
</RowCount>
<Lookup Name="LKP Historical Key" NoMatchBehavior="RedirectRowsToNoMatchOutput"
OleDbConnectionName="<#=DstConnection#>">
<DirectInput>SELECT
CONVERT(VARCHAR(34), ChangeHashKey, 1) AS ChangeHashKeyASCII
, CONVERT(VARCHAR(34), HistoricalHashKey, 1) AS HistoricalHashKeyASCII
FROM
<#=DstSchemaName#>.<#=DstTableName#></DirectInput>
<Parameters>
<Parameter SourceColumn="HistoricalHashKeyASCII" />
</Parameters>
<ParameterizedQuery>select * from (SELECT
CONVERT(VARCHAR(34), ChangeHashKey, 1) AS ChangeHashKeyASCII
, CONVERT(VARCHAR(34), HistoricalHashKey, 1) AS HistoricalHashKeyASCII
FROM
<#=DstSchemaName#>.<#=DstTableName#>) [refTable]
where [refTable].[HistoricalHashKeyASCII] = ?</ParameterizedQuery>
<InputPath OutputPathName="CNT Source_Rows.Output" />
<Inputs>
<Column SourceColumn="HistoricalHashKeyASCII"
TargetColumn="HistoricalHashKeyASCII" />
</Inputs>
<Outputs>
<Column SourceColumn="ChangeHashKeyASCII"
TargetColumn="lkp_ChangeHashKeyASCII" />
</Outputs>
</Lookup>
<OleDbDestination Name="OLE_DST New_Rows" ConnectionName="<#=DstConnection#>">
<InputPath OutputPathName="CNT New_Rows.Output" />
<ExternalTableOutput Table="<#=DstSchemaName#>.<#=DstTableName#>" />
</OleDbDestination>
<RowCount Name="CNT Source_Rows" VariableName="User.RowCountSource">
<InputPath OutputPathName="<#=DataFlowSourceName#>.Output" />
</RowCount>
<OleDbSource Name="<#=DataFlowSourceName#>" ConnectionName="<#=SrcConnection#>">
<DirectInput><#=SourceQuery#></DirectInput>
</OleDbSource>
<RowCount Name="CNT Unchanged_Rows" VariableName="User.RowCountUnchanged">
<InputPath OutputPathName="CSPL Check For Changes.Default" />
</RowCount>
<OleDbDestination Name="OLE_DST Update Table" ConnectionName="<#=DstConnection#>">
<InputPath OutputPathName="CNT Changed_Rows.Output" />
<ExternalTableOutput Table="[<#=UpdateSchemaName#>].[<#=UpdateTableName#>]" />
</OleDbDestination>
</Transformations>
<PrecedenceConstraints>
<Inputs>
<Input OutputPathName="SQL Truncate <#=UpdateTableName#>.Output" />
</Inputs>
</PrecedenceConstraints>
</Dataflow>
<ExecuteSQL Name="SQL Update <#=DstTableName#>"
ConnectionName="<#=DstConnection#>">
<DirectInput><#=UpdateSQLStatement#></DirectInput>
<PrecedenceConstraints>
<Inputs>
<Input OutputPathName="DFT Insert<#=DstTableName#>.Output" />
</Inputs>
</PrecedenceConstraints>
</ExecuteSQL>
<ExecuteSQL Name="SQL Close Audit" ConnectionName="Audit">
<VariableInput VariableName="User.QueryAuditUpdate" />
<Parameters>
<Parameter Name="0" VariableName="System.PackageID" DataType="Guid" Length="-1"/>
<Parameter Name="1" VariableName="System.ServerExecutionID" DataType="Int64"
Length="-1"/>
<Parameter Name="2" VariableName="User.RowCountNew" DataType="Int32" Length="-1"/>
<Parameter Name="3" VariableName="User.RowCountChanged" DataType="Int32"
Length="-1"/>
<Parameter Name="4" VariableName="User.RowCountUnchanged" DataType="Int32"
Length="-1"/>
</Parameters>
<PrecedenceConstraints>
<Inputs>
<Input OutputPathName="SQL Update <#=DstTableName#>.Output" />
</Inputs>
</PrecedenceConstraints>
</ExecuteSQL>
</Tasks>
</Package>
CreateDim1.Biml
<#@ template language="C#" hostspecific="true" #>
<Biml xmlns="http://schemas.varigence.com/biml.xsd">
<#@ include file="ProjectConnection.biml" #>
<!--
<#
string PackageName = "LoadDimSalesReason";
string DstSchemaName = "dbo";
string DstTableName = "DimSalesReason";
string DstConnection = "AWBIML";
string DataFlowSourceName = "OLE_SRC StgDimSalesReason";
string SrcConnection = "AWBIML";
string SourceQuery = @"SELECT [SalesReasonID]
,[SalesReasonName]
,[SalesReasonType]
,[HistoricalHashKey]
,[ChangeHashKey]
,[HistoricalHashKeyASCII]
,[ChangeHashKeyASCII]
,[InsertDttm]
,[UpdtDttm]
FROM [AWBIML].[Staging].[DimSalesReason]";
string UpdateSchemaName = "Updt";
string UpdateTableName = "UpdtSalesReason";
string UpdateConnection = "AWBIML";
string UpdateSQLStatement = @"Update d
set
d.SalesReasonName = u.SalesReasonName,
d.SalesReasonType = u.SalesReasonType,
d.changehashkey = u.changehashkey
FROM Updt.UpdtSalesReason u
inner join dbo.DimSalesReason d
on u.HistoricalHashKey = d.HistoricalHashKey;";
#>
-->
<Packages>
<#=CallBimlScript("Dim1.biml", PackageName, DstSchemaName, DstTableName, DstConnection,
DataFlowSourceName, SrcConnection, SourceQuery, UpdateSchemaName, UpdateTableName,
UpdateConnection, UpdateSQLStatement)#>
</Packages>
</Biml>
Resulting SSIS Package
Executing the CreateDim1.Biml file generates a package called LoadDimSalesReason.dtsx. Here is the control flow:
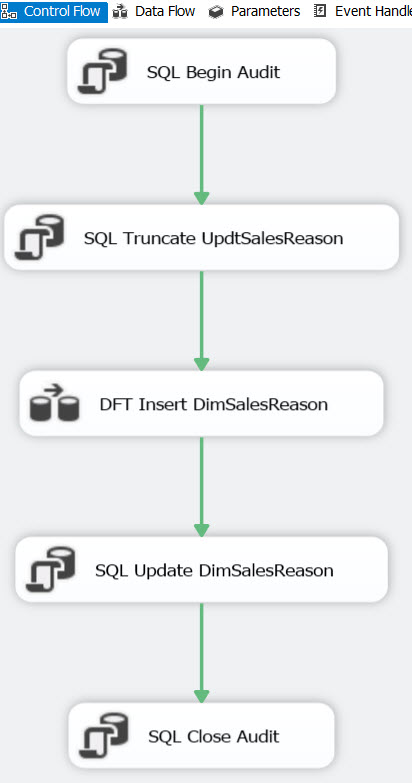
I start the package by logging the package start in my PackageControl table. Then I truncate my update table to prepare for the new data load. Next I have a data flow task, which inserts data into either the dbo.DimSalesReason table or the Updt.UpdtSalesReason table (see below). The SQL Update task updates the DimSalesReason table with the rows that were inserted into UpdtSalesReason. And finally, I log my package completion.
Here’s my data flow:
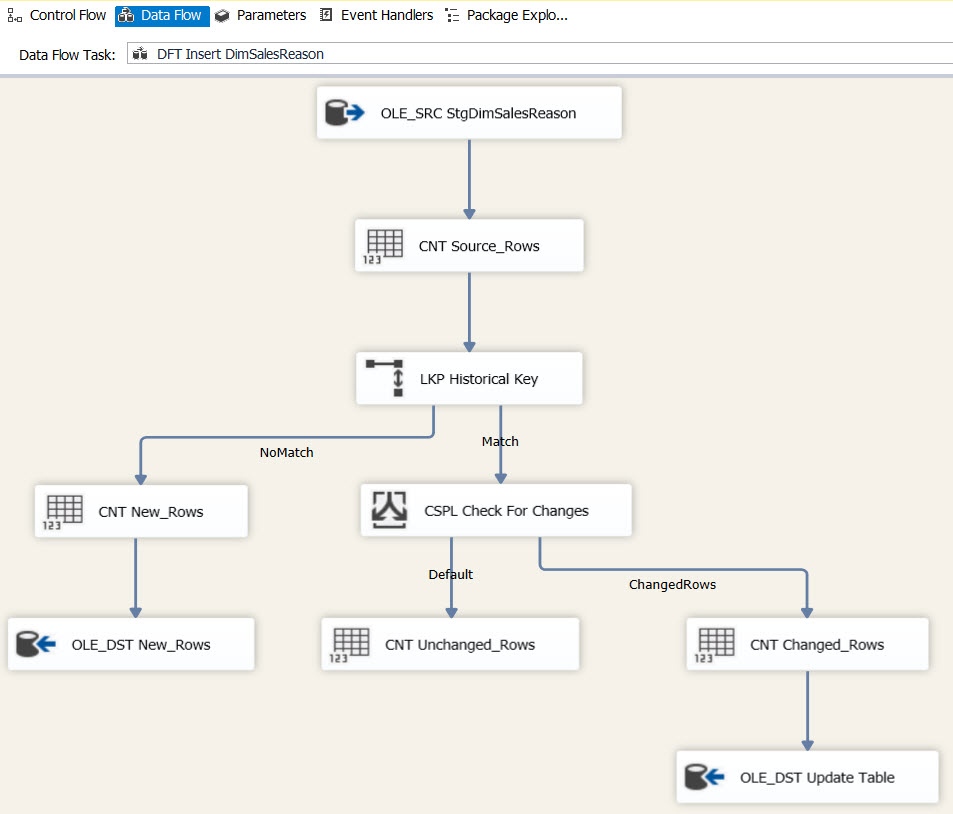
First, I retrieve my data from my staging view. Then I count the number of rows coming from my source so I can log it in my PackageControl table. The lookup on the HistoricalHashKey field sends rows with no match to be inserted into the dimension table. If the rows have a match, they are checked to see if their ChangeHashKey values match the value of the ChangeHaskey in the existing row in the dimension table. If ChangeHashKey values match, the row is counted and nothing else is done. If the ChangeHashKey values don’t match, the row is counted and written to the update table.
And that is all you need to create a Type 1 dimension load with Biml.
Slight bug in your CreateDim1.biml. The UpdateSQLStatement should be:
UPDATE d
SET d.SalesReasonName = u.SalesReasonName ,
d.SalesReasonType = u.SalesReasonType ,
d.ChangeHashKey = u.ChangeHashKey ,
d.UpdateDttm = CURRENT_TIMESTAMP
FROM Updt.UpdtSalesReason u
INNER JOIN dbo.DimSalesReason d ON u.HistoricalHashKey = d.HistoricalHashKey;
ie swap round which table is being updated. In your version UpdtSalesReason gets the value from DimSalesReason. It should be the other way round, as above. And update UpdateDttm too 😉
Ah, I just aliased them backwards. That’s what I get for typing late at night. Thanks for catching that. It should be fixed now.
thanks your article!
I’m looking for an example using the ssis built-in scd task. Why idea where could find that?
What I have right now (reverse engineered by mist) generates a biml engine error.
Sorry, I don’t know anyone who uses the built-in SCD task. Although it has gotten better, it’s been very inefficient in the past. I have biml posted for you to do a Type 2 or 6 SCD on this blog through the use of hash keys. https://datasavvy.wordpress.com/2015/12/20/demystifying-the-type-2-slowly-changing-dimension-with-biml/ and https://datasavvy.wordpress.com/2015/12/26/type-6-or-hybrid-type-2-slowly-changing-dimension-with-biml/
Hi Meagan,
thanks for the great detail of your post(s), I was looking for a smart solution and yours was very helpful!
I’d like to tweak it a little bit and implement it in my environment (a manufacturing company in Italy), making extensive use of metadata from system tables like sys.columns, sys.tables, and so on, as I have already done while building the staging environment.
My goal is to automatize most, if not all, of the process of building the BIML files and the SSIS solution.
I’d also love to submit a talk to a SQL Saturday, presenting the resulting solution. May I use your work as a basis for the talk?
Thanks again for the post!
Sure! Feel free to use any Biml from my blog and improve upon it for your environment, SQL Saturday talks, or future blog posts.
Thanks Meagan!
Hi Megan
first of all I wanted to thank you for this article as you can see five years later people are still reading it.
I have a question regarding your lookup in a big environment. Using the convert function for #keys and you are therefore not able to Index your keys. Are you nnot getting any performance issues and if you had one how do you deal with it?
Thanks for your time and efforts!
Hi, Josef. I haven’t had a performance problem with that lookup. That might be because my data load is usually only pulling in the relevant data for that load (probably small or incremental). This pattern is actually easier in T-SQL where you don’t have to convert the binary to a varchar and you can just do a WHERE EXISTS. If I remember correctly, converting to string was to work around the SSIS limitation of not supporting binary data types in the conditional split. An alternative is to have a persisted computed column in the table and put an index on that. That is basically the only place the hashkeys are used (for change detection in the ETL). The views and also user queries would use the business and surrogate keys, which is where my indexes are.